Hyperparameter Space






It’s no secret that there’s something broken about how science is published and disseminated. Behind each paper there’s a hefty body of work, revisions, unpublished data, and back-and-forth argumentation that doesn’t make it to the final version. Unless a preprint is published or an openly-reviewed avenue is chosen (e.g. eLife, OpenReview, or the various journals that choose post-publication peer review), the whole discussion between authors and reviewers remains behind closed doors. Even when the information is open, the discussions already happened, and mostly with a limited number of reviewers that may or may not be familiar with the context of the work in questions (particularly the case in fields where reviewers are scarce). It’s no surprise then when several groups publish basically the same idea, or scoop each other, or play a weird game of trying to guess who is the reviewer to see if it is a competitor, or falsified but informative hypotheses go unpublished. From time to time, I see one of these bad things happen and recall the myriad conversations with colleagues about open science and reproducibility and how to tackle it all. Almost always the solutions proposed are inspired by the concept that lies at the core of how software is made: version control (just check out Richard McElreah’s fantastic talk on this topic). Version control is one of the best inventions of the software industry and was born out of a necessity to track increasingly complex codebases across multitudes of developers – a system that has been refined for decades to allow for open and distributed collaboration. A few days ago my mind was hovering around such topics and I wrote a small twitter thread:
We need a github for hypotheses, where one would register a thesis. Subsequent commits would be data and arguments against or in support of it. Eventually "releases" become papers.
— Pablo Cordero (@tsuname) August 22, 2021
Are you sceptical of my hypothesis or found something cool? Do a pull request.
It was mostly to get the rant out of my chest, but I was surprised by the response. It seems that there are many people that arrive at the same conclusion: the scientific process should be version controlled. Some have even already created products based on the idea. It’s hard not to see why. GitHub and other version control platforms have in many ways nailed down both the process, the usage, and the structure of how software should be created, revised, and released. It feels so smooth these days to interact with remote teams and review the work of people you might not even know to work towards building open tools. Every commit, every branch, and every pull request forms the whole history of how a software artifact was built. If your tool matters it will be peer reviewed multiple times by people who want it to work. It really feels like what the process of scientific research, of constant refinement of hypotheses and incorporation of evidence, should be.
I was both pleasantly surprised to hear about all the nice tools out there that drive this idea and somewhat puzzled and disappointed by why these tools are not taking off with the speed matching the supposed demand that I hear. First, let me go through some tools and platforms that I found out about after that discussion (if I’m missing your favorite one, let me know and I’ll update!):
- OSF (The Open Science Framework): Created by the Open Science Foundation, it’s basically a file/dataset/visualization tracker and versioning system. It does have cool features like hosting datasets and aggregating citations, though browsing other people’s projects can be harder than e.g. browsing github trends.
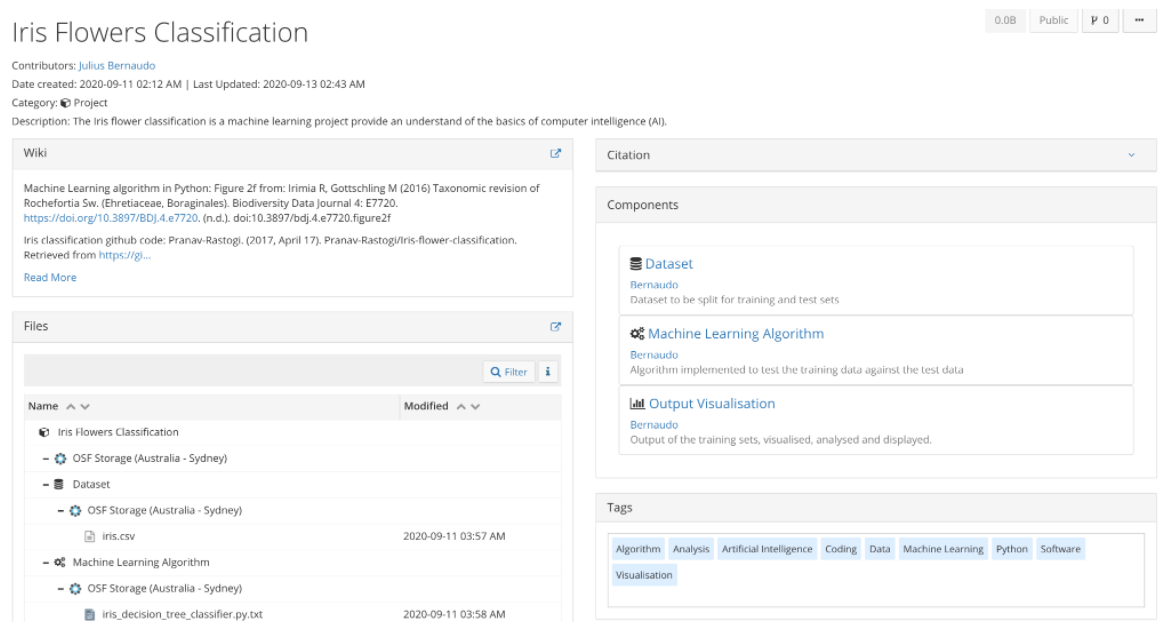
- Science Octopus: Although it seems sort of new, this was actually created back in 2018 and it looks a lot more like what I would expect from version controlled hypotheses. It makes a clear distinction between problems, the hypotheses for tackling them, and the process of validating or disproving said hypotheses. It also links multiple problems and has a friendly interface to search and explore.
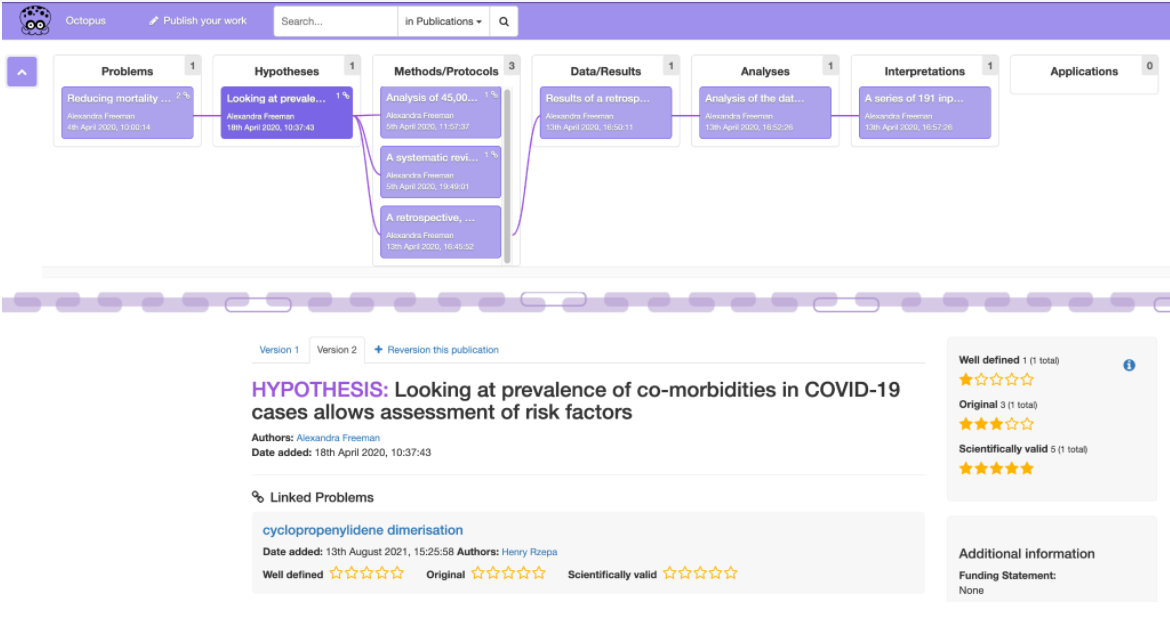
- Hypergraph: Still in early stages, looks like hypergraph is an app that organizes files and links projects together to explore a graph of scientific projects. There seems to be some integration with science octopus in the works.
- Atoms.org: Yet to launch but a very interesting manifesto/roadmap taking a holistic view of the scientific enterprise. There’s a lot in there to discuss as their goal seems to be to realign what they call the “research economy” via smart contracts with different “atoms” such as prizes, grants, and tenure, all incentives that are connected to some proof-of-work like data and contributions to the research community. The interesting part is that it seems a more decentralized and “atomic” approach to science would stem from this economic design, much in the way other markets are incentivized to publish good news early and often.
- Github itself: Github is already more than capable of handling the workflow that encompasses a scientific project. Pull requests become contributions or challenges to data analysis interpretations, issues are yet-to-be addressed work by outside reviewers, and releases are manuscripts to be submitted. This has been done successfully multiple times in many labs resulting in some evergreen papers and reviews. Perhaps the missing part connecting multiple repositories representing scientific hypotheses together.
How can we make adoption of version controlled science go faster?
While version control has existed for a long time, the platforms above are relatively recent, and adoption of publication techniques in many corners of academia and even industry takes a while to take hold. It is quite possible that we are looking at the first versions of many until we see a platform that is widely adopted. A similar thing happened to preprints: the idea of a preprint has been around for more than 30 years yet preprints have been adopted in biomedicine and chemistry until relatively recently. Taking the step further to a more refined form of peer review of collaboration such as version controlled science might take a few more years of constant advocating.
Or will advocating be enough? It might make sense to take a look at how similar movements succeeded. Perhaps a good case study is the open source software movement, which at first started as a disperse set of groups dissatisfied with the monopolies of developer unfriendly software but then became the standard across the board. The success of open source can be perhaps attributed to grass-roots momentum at first, which created software that was as good or better than closed alternatives, and corporate stewardship for its dissemination in the later stages. High quality and the “made for developers by developers” feeling of the resulting products were key. What would be the scientific equivalent? The scientific projects adopting version controlled science will have to necessarily be of higher quality and more open to collaboration. They will have to be widely broadcasted and include rather than compete with adjacent groups asking the same question. But this might not be enough. Funding and administrative entities will have to buy in the concept as well, perhaps persuaded that version controlled science is better science, and selecting for grantees that adopt that strategy. Bottom-up effort will have to be followed by top-down stewardship, much like how repositories of open data like GEO, SRA, and others were both advocated by top scientific groups and enforced by funding agencies.
One can perhaps argue that the first step is already being taken: it is qualitatively the case that collaborative scientific groups with open codebases, and pre-reviewed dissemination tend to be the most successful ones. Computational groups, whose research is tied with actual software, already do this one way or another as they version control their packages and releases. The next step is perhaps to have advocates in those groups to further open up the process and track hypotheses and data in the open, and encourage collaboration organically. How different scientific communities react to such changes will be telling of the true appetite for openness and collaboration. As a reference, it is interesting to note that the adoption of preprints in biomedicine and chemistry has been exponential, suggesting that while the perceived top-down incentives were low (e.g.there was a lingering doubt in whether journals, funding agencies, and competing groups would see preprints in a negative light), bottom-up demand for a faster route to dissemination and collaboration was already there and just needed to be “released”.
This matters in every corner where science is used
The scientific process of critique and publication is intimately associated with academia and specialized research groups. However, we must note that this is far from the only place where science is used as a driver. As data science has matured, the use of scientific methodologies to answer key business drivers has increased. Data first companies increasingly have teams of people devoted to answer questions beyond simple A/B tests and more nuanced methodologies like causal inference are now routinely outside specialized groups. Many of these companies are big enough that large data teams need internal publication and dissemination venues to communicate with each other. Disciplined version controlled science would be a boon in these settings and might address a similar need that agile and lean methodologies addressed in software engineering.
We just need to try it
Everyone I talk to agrees one way or another that we need this sort of change for science to prosper. But what if everyone I talk to is wrong? What if version controlling science results in just more bureaucracy and just gets in the way? After all, research projects are notoriously messy, even more so than coding endeavors. Version control can also result in lots of red tape depending on the organization. What’s clear is that the current methods of doing science in all settings seems more than a bit outdated considering the tools we now have to track projects, enable collaborations, and assess progress. Trying things outside the status quo will be necessary to modernize how we rally around for research projects, we just need to give it a spin and assess the results.