Hyperparameter Space






I really can’t help but smile when hearing folks talking about causal models recently. It looks like causal models are making a comeback! This is a pleasant surprise to me, since I’ve always been a fan of causal inference and I wasn’t sure Judea Pearl’s “Book of Why” was going to catch up or not. But now we even have Pearl on Twitter and there’s more light being shed on work that leverages causal models for various problems or that scales them to very high dimensional settings. We even get new python packages (e.g. Microsoft’s DoWhy)! Rightly so, there’s talk on testing machine learning models on data distributions that they were not trained on, to strain-test them properly, and this is the setting where causal models excel. But the main lure of causal models is that they make explicit claims of the nature of the world – they state not only the process by which the observed is generated, but also what happens under intervention of each of the variables, surfacing the alternative, counterfactual, ‘what if’ routes that the state of the world could be in. In this sense, it is a much more complete picture of reality than, say, conditional probability distributions. Further, it allows for generating potentially testable predictions to falsify or verify our view of the world.
What is a causal model? In simple terms, it’s the statement that some/all conditional relationships between variables in a statistical model are causal. This mainly implies that if you state that $X \rightarrow Y$, then you’re saying that performing interventions on $X$ will have an effect on $Y$ necessarily (which is different than stating that $Y$ conditioned on $X$ has a certain form/shape, this would be a ‘correlation-based’ statement that applies only on samples on that distribution, whereas $X \rightarrow Y$ is a causal statement that applies to samples outside of the observed distribution). Ferenc Huzar as always has a very good post on the definitions of causal models and their difference with conditional distributions.
The satisfying thing about causal models is their rigor: they make explicit your core assumptions about your data and modeling. If you’re like me, you might have first been exposed to probability/stats through some applied area, like computational biology or machine learning. At first, the problem of inference looks conceptually straightforward: optimize a loss function $L$ that summarizes your assumptions about your data and the task you’re trying to solve.
$$\arg\min_{\theta} L(\theta)$$
You might have then been exposed to Bayesian statistics. Then things start to get interesting. Turns out that you may be hiding some constants in your loss function, or making assumptions about your data if you regularized in any way.
$$\arg\min_{\theta} L(\theta) + R(\theta) + Z$$
These are your priors and what you’re trying to optimize is actually some form (e.g. the log) of the posterior distribution. You are also hiding a constant in your data, the partition function $Z$ that actually makes the posterior an actual distribution. Superficially, nothing has changed, your problem is still an optimization problem, your loss function is still the same. But your conceptual understanding of it is transformed and has important implications. This posterior distribution might actually represent your belief in your inferred parameters. If so, shouldn’t you be getting the actual shape of your posterior distribution instead of optimizing it? This is the core of Bayesian statistics and if you want to follow that path it has implications on how you do your inference (as in you have to figure out how to infer an entire distribution which is in general a lot more difficult than point estimation).
Causal models are a similar conceptual jump. Even if you put your inference task under a rigorous Bayesian model, you are limited only to the data distribution you infer from, and any relationships between your variables at the end of the day will be statistical, all bets are off with any extrapolation you make from your model. In truth, one’s goal is rarely just to find statistical correlations, it almost always is to gain an understanding of how something works (or to build a machine that has an understanding of how something works). More often than not, you want to find out relationships that generalize outside of your distribution. What you really want to find out is whether variations in the gene that you have studied for years really do cause late cell phone adoption. What you really want to find out is whether your drug treatment worked, or whether your machine learning model is really unbiased. These are not statistical models, these are causal models: dependencies and assumptions that describe the chain of events we are interested in. We keep saying that we understand that correlation is not causation, but almost always we do hope it does.
Just like going from just a loss function to a Bayesian posterior, taking into consideration causal models might change how we perform our inference. If we now know that we need to find out not $P(Y|X)$ but its interventional cousin $P(Y|do(X))$, then we must put our causal assumptions on the table and consider whether this is even feasible from the observed data. If not, then we might end up stating something about $P(Y|X)$, but with warnings to whoever uses this model, caveat emptor, or that we that we need to run a randomized experiment. As with Bayesian statistics, the power is more conceptual. It is a more honest way to convey the results of the analyses.
Intervention and counterfactuals
The causal dependencies between variables that compose causal models can be used to predict two main quantities of interest. The first one is the probability of intervention $P(Y|do(X))$, which is the probability of observing $Y$ when you intervene in the real world and set the value of $X$, and represents the total effect of that intervention. The second one is a generalization of this intervention mechanism, in which we are allowed to imagine a counterfactual world where not only $X$ changes value, but maybe some other variables as well, including mediating variables like $M$ in $X \rightarrow M \rightarrow Y$ are also set to whatever we want. Interventions are in a way the most simple of (non-trivial) counterfactuals.
When we are interested in interventions, that is in the $P(Y|do(X))$ quantity, we may want to know things like whether, say, a treatment actually had any effect on a given disease. This question can be answered with a randomized experiment, by separating your population into random groups, intervening on them in different ways, and observing the results. This is many times infeasible due to ethical or cost concerns. However, if you assume that your causal model has certain structure, then you might be able to calculate $P(Y|do(X))$ given just observations of $P(Y| X)$. There are many ways to do this, but the following three are the ones I’ve seen the most:
 Left: Illustration of instrumental variables and the backdoor criterion. U is an unstrumental variable of $X \rightarrow Y$, while $Z$ blocks all backdoor paths from $X$ to $Y$, making it a confounder that can be leveraged to estimate the intervention effects of $X$ on $Y$ using observational data. Middle: the classic frontdoor criterion where $Z$ is the “front door” from $X$ to $Y$, allowing for an adjustment to estimate the effects of $X$ on $Y$ even if a confounder, $U$, is unobserved. Right: An example where no criterion can be used to calculate the effects of $X$ on $Y$ as there are backdoor paths blocked by an unobserved variable $V$, there are no instrumental variables, and no variables that act as front doors.
Left: Illustration of instrumental variables and the backdoor criterion. U is an unstrumental variable of $X \rightarrow Y$, while $Z$ blocks all backdoor paths from $X$ to $Y$, making it a confounder that can be leveraged to estimate the intervention effects of $X$ on $Y$ using observational data. Middle: the classic frontdoor criterion where $Z$ is the “front door” from $X$ to $Y$, allowing for an adjustment to estimate the effects of $X$ on $Y$ even if a confounder, $U$, is unobserved. Right: An example where no criterion can be used to calculate the effects of $X$ on $Y$ as there are backdoor paths blocked by an unobserved variable $V$, there are no instrumental variables, and no variables that act as front doors.
Instrumental variables
If you are in luck and you posit that the relationship between $Y$ and $X$ is linear, and you have another variable $Z$ that you know affects $Y$ only through $X$ also in a linear fashion, then $Z$ is called an instrumental variable and the causal effect $X \rightarrow Y$ can be calculated using a two-stage linear regression, where you first solve $Z = \alpha X + \epsilon_1$ and then solve $Y = \beta X + \epsilon_2$ by replacing $X$ with the result of the first regression. When the relationships above are not linear, $Z$ is also an instrumental variable but in general it’s not possible to use it to estimate the final causal effect. This limits the use (and conclusions obtained via) instrumental variables, since, remember, we are stating that the actual, true relationships are linear (bets are off for statements such as ‘linear approximations’).
The backdoor criterion
This is one of Pearl’s do-calculus rules, and it’s a pretty neat result. Essentially, it states that when accounting for any variables that confound $X$ and $Y$, observing is the same as interventions. The “backdoor” name comes from the condition that all such confounders $Z$ must block all “backdoor” paths that begin in arrows pointing at $X$ and end at $Y$. In this case, we then have that $$P(Y|do(X) = x) = \sum_{z} P(Y | X = x, Z = z) P(Z = z)$$.
The frontdoor criterion
The counterpart of the backdoor criterion, where a variable $Z$ mediates the interaction between $X$ an $Y$ by blocking all directed paths (e.g. $X \rightarrow Z \rightarrow Y$). Additionally, $X$ must block all backdoor paths from $Z$ to $Y$ and there must be no backdoor paths from $X$ to $Z$. Then, we have that:
$$P(Y|do(X) = x) = \sum_z P(Z=z|X=x) \sum_w P(Y|X=w,Z=z)P(X=w)$$
In this case, the frontdoor name comes from the fact that $Z$ is the front and really only variable that mediates the interactions between $X$ and $Y$.
Counterfactuals
Quantities that do not only depend on $P(Y|do(X))$ but on any arbitrary combination of counterfactual situations where we can imagine any intervention that we want are in the general case not only not possible to identify with observational data, but may be out of reach of any experimental design. Thus, counterfactuals prove useful in cases where either (1) they can be estimated from observational data (by being reduced to expressions containing do-operators with a certain structure) or (2) they can be falsified via further experimentation.
Learning causal models from scratch
So far we have assumed that we already have a causal model in mind when analyzing the data. But what if we don’t? Can we estimate the best causal model from the data? Turns out, there is indeed a way to score a causal model given the data. The concept linking the two is d-separation (short for dependance separation). In a nutshell, d-separation states that $X$ and $Y$ are separated by $Z$ under specific graphical conditions if and only if $X$ and $Y$ are observed to be conditionally independent given $Z$ (I won’t review the graphical conditions of d-separations here, but you can find it in Pearl’s Causality). This establishes a way to score the model given the data: just pick a scoring function that evaluated the conditional structure of your variables assuming the causal dependencies. Importantly, however, various causal models can have the same d-separation relationships between variables and will therefore score the same given the data. These are called Markov equivalence classes and algorithms that try to learn causal structure typically involve a smart way of sampling these classes to speed up the search.
Some applications of causal models
Scenarios with rapid, continuous feedback
Testing causal models almost always involves positing and running experiments. In the best of cases, we will have a system where we can quickly perform experiments and gauge the outcome in a continuous fashion. For example, in model-based reinforcement learning, the agent is constantly evaluating its current model given the state of the world and its actions. We can cast the task of learning the value function as a causal inference task, in which the current state of the agent $S$ causes some difference in state and reward in the next step $\Delta$ that in turn causes a change in the expected reward $r$. Shakir Mohamed has a great post detailing this scenario using intstrumental variables.
With a slower, but still fast, ability to test models, assessing the impact of an intervention in web site and product traffic is also a big area of application and one in which causal models are used a lot. For example, assessing the impact of the introduction of a recommender system or a marketing campaign while accounting for possible confounders (like seasonality) is the specialty of causal models.
Quantifying model bias
This is a clever application I was aware of only recently. One of the main worries of deploying machine learning models for critical decision making is bias that leaks from the training data to the model. What if we wanted to streamline hiring processes using historical data? The resulting system may end up learning discriminatory practices. One way to test whether the recommendations are biased is putting the black box algorithm as a variable inside a causal model and testing whether certain variables, like gender and ethnicity, have a causal effect on the model’s predictions. This paper discuss this approach and the interesting considerations one must make when using causal models as a testing ground for black box decision makers.
Data integration
One of the favored approaches in computational biology to almost any problem in bio is data integration. There are just a lot of disparate biomedical datasets out there each which might contain pieces of the answer for a question you might have. For example, say you want to know whether a particular drug will be effective in treating some disease. In the most informative of worlds, you would have all sorts of drug measurements and disease marker responses available for a big human population. But this is unethical and generally infeasible. In this case, your causal diagram would look something like this, where the relationship you’re interested in is drug to disease:
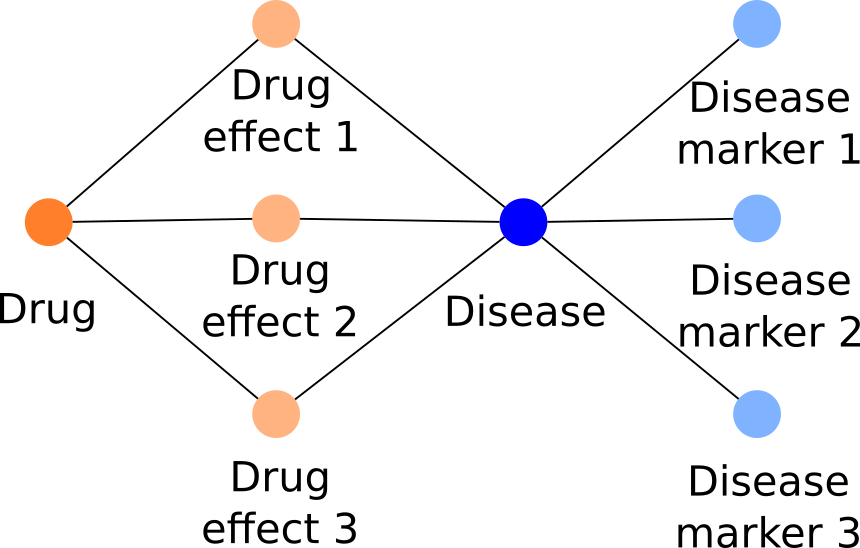
However, you can still use a lot of data sources to give you hints here and there of whether the drug modulates the disease. You could, for example, interrogate whether perturbation of the known gene/protein targets of the drug affect a cell line model of your disease. You can also ask whether the drug rescues some disease marker/phenotype in a mouse model; or whether another disease marker in a cell line is affected by exposure to the drug. We can collapse our previous causal model into a simpler one, in which both drug and disease are variables that are confounded by a ‘measurement type’:
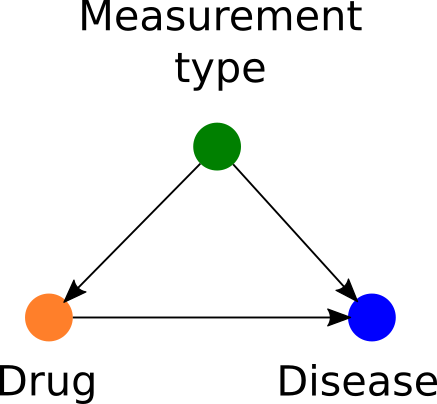
We can then apply the backdoor criterion to quantify the causal influence of the drug on the disease. Interestingly, the backdoor criterion tells us that:
$$P(disease|do(drug)) = \sum_{MT} P(disease|drug, MT)P(MT)$$
Where $MT$ is the measurement type. Notice, that this is simply weighing our conditional of disease to drug and $MT$ by a prior that we can put on the measurement type. In a way, we can use this to control how much we believe in that type of measurement (e.g. you might believe your mouse model more than your cell line model). Assuming linear relationships and Gaussian likelihoods, this model is easy to code and compute – it’s simply a pair of least squares regresion problems. But what if we had a more complex model where we think the relationships are non-linear? We can leverage a probabilistic programming framework like Edward2 for this purpose, using neural networks as non-linear regressors:
import tensorflow as tf
import tensorflow_probability as tfp
from tensorflow_probability import edward2 as ed
tf.reset_default_graph() # -> for notebooks you might want to reset the graph
# This follows in the spirit of Tran and Blei's work on implicit causal models
# in GWAS, https://arxiv.org/abs/1710.10742
# Declare the types of measurements we can have, as in the text above
# 1. Target knockout stands for performing knockout perturbation in e.g. a cell
# line of one or many of the drug's targets and measuring the response
# 2. Mouse or 3. cell line models of the disease and their response to the
# presence of the drug
MEASUREMENT_TYPES = ['target_knockout' ,
'mouse_drug_treatment',
'cell_line_treatment']
# Each measurement type will have different number of features, we will need
# to "put them on the same page" and collapse/encode them to a standard number
# of features -- let's do 20
NUM_FEATURES = 20
# Function to encode our measurement types to a vector. We use a simple one-hot
# encoding here.
def measurement_type_encoder(measurement_type,
num_samples):
return tf.one_hot([MEASUREMENT_TYPES.index(measurement_type)]*num_samples,
depth=len(MEASUREMENT_TYPES))
# Encoder to standardize our number of features per measurement type.
# We use a simple, dense neural network for this purpose.
# Alternatively, we could pre-encode the different measurement types via some
# transfer learning framework (e.g a la word embeddings for NLP)
def drug_measurement_encoder(drug_measurement,
measurement_type):
N = drug_measurement.shape.as_list()[0]
h = tf.layers.dense(drug_measurement,
64,
activation=tf.nn.relu,
name=measurement_type + '_layer_1',
reuse=tf.AUTO_REUSE)
h = tf.layers.dense(drug_measurement,
64,
activation=tf.nn.relu,
name=measurement_type + '_layer_2',
reuse=tf.AUTO_REUSE)
h = tf.layers.dense(h,
NUM_FEATURES,
activation=None,
name=measurement_type + '_layer_3',
reuse=tf.AUTO_REUSE)
return tf.reshape(h, [N, NUM_FEATURES])
# The measurement_type -> drug dependency
def drug_dependencies(encoded_measurement_types, N):
h = tf.layers.dense(encoded_measurement_types,
64,
activation=tf.nn.relu,
name='drug_meas_type_layer_1')
h = tf.layers.dense(h,
NUM_FEATURES,
activation=None,
name='drug_meas_type_layer_2')
return tf.reshape(h, [N, NUM_FEATURES])
# The drug & measurement_type -> disease model
def drug_disease_model(encoded_measurement_types):
N = encoded_measurement_types.shape.as_list()[0]
# This will later be linked to the encoded drug measurement data
drug_var = ed.Normal(loc=drug_dependencies(encoded_measurement_types, N),
scale=1,
name='drug_dependencies')
h = tf.layers.dense(drug_var,
64,
activation=tf.nn.relu,
name='disease_response_layer_1')
h = tf.layers.dense(h,
len(MEASUREMENT_TYPES),
activation=tf.nn.relu,
name='disease_response_layer_2')
h = tf.concat(encoded_measurement_types + [h], 0)
h = tf.layers.dense(h,
1,
activation=None,
name='disease_response_layer_3')
h = tf.reshape(h, [N])
# This will later be linked to the disease response data
return ed.Normal(loc=h, scale=1, name='disease_response')
# Generate some data. In the real world we would have to preprocess the data of
# each measurement type to put them on the same dynamic range/scale.
measurement_types = ['target_knockout',
'target_knockout',
'mouse_drug_treatment',
'cell_line_treatment']
num_samples = [50, 20, 60, 200]
num_dims = [50, 50, 10, 10]
drug_measurements = []
disease_response = []
for i, mt in enumerate(measurement_types):
drug_measurements.append(tf.random_normal([num_samples[i], num_dims[i]]))
disease_response.append(tf.random_normal([num_samples[i], 1]))
# Encode the measurement types and drug measurements
drug_meas_enc, meas_type_enc = [], []
for dm, mt in zip(drug_measurements, measurement_types):
drug_meas_enc.append(drug_measurement_encoder(dm, mt))
meas_type_enc.append(measurement_type_encoder(mt, dm.shape.as_list()[0]))
encoded_measurement_types = tf.concat(meas_type_enc, 0)
encoded_drug_measurements = tf.concat(drug_meas_enc, 0)
# Do a test run of the generative model to see that we wired everything
# correctly.
with tf.Session() as sess:
disease_response_ = drug_disease_model(encoded_measurement_types)
sess.run(tf.global_variables_initializer())
sess.run(disease_response_)
# We can then learn the parameters in the generative model by linking
# the encoded drug measurements to the drug_dependency variable in the
# computation graph and the disease_response data to the disease_response
# variable.
# In edward2 this is typically done by first generating the log joint prob
# function via a built-in helper...
log_joint = ed.make_log_joint_fn(drug_disease_model)
# ... then wrapping that up in a function to optimize
def log_joint_to_optimize(measurement_type_layers,
disease_response_layers):
param_mapping = {}
for layer_name, layer in measurement_type_layers:
param_mapping[layer_name]= layer
for layer_name, layer in disease_response_layers:
param_mapping[layer_name] = layer
# Link our remaining data to the relevant variables
param_mapping['drug_dependencies'] = encoded_drug_measurements
param_mapping['disease_response'] = disease_response
return log_joint(drug_measurements,
measurement_types,
**param_mapping)
# ...
# ...
# Use log_joint_to_optimize with your favorite approach e.g. sampling with MCMC
# or a maximum a posteriori via built-in optimizer, etc. ...There are lots of things we can do to fine tune our model (e.g. adding priors to our parameters) and to scale it to really big datasets, but these are all tasks of statistical modeling. Our causal model remains the same simple triangle above.
Some caveats of causal models
The causal model framework is not without its critiques. I can think of three particular examples with interesting ramifications:
What is an intervention, really?
When we talk about interventions of a do-operator, what are actually talking about? I’ve seen Pearl define it as the minimal intervention required to change the variable. But what exactly is a minimal intervention? Shouldn’t we model the intervention itself, as it may have unexpected consequences in other parts of the model? This is something that folks in policy bring up a lot, since their interventions via policies can be very blunt instruments that change multiple variables. To be honest, even if you can think of very precise interventions (like changing a single nucleotide in a genome via a magical enzyme), it is likely that you’re not thinking about unexpected consequences (no enzyme, no matter how magical, has no off-target effects in some way or another). Minimal interventions are an assumption that we must contend with when using do-calculus.
The siren call of structure learning
Learning the structure of a causal model from scratch is an appealing idea for exploring causal models in an unbiased manner. But structure learning is hard. As in super-exponentially hard. There’s no generalizable way to efficiently sample equivalence classes and even if you can there’s a good chance there are many models that will fit your data equally way. Even if you do have a high-scoring causal model, how do you interpret it? Usually causal models are the condensation of several insights from many experiments. Unpacking a causal model is almost an ill-defined task. I think this sort of tripped up many folks in comp bio a few years ago. I started my PhD at the time where Bayesian networks were all the rage in genomics and computational folk were using them to try to understand how gene networks were wired at the large scale. At this time, some foundational results in gene expression, networks, and regulation (like any of Johan Paulsson’s or Uri Alon’s works) had been consistently derived from laborious time-lapse fluorescence experiments with a few genes and there was hope that some similar insights could be gained from high-throughput genomic datasets, where thousands of genes were observed at the same time, albeit in few samples and almost always with no temporal information. The field of gene network inference was all into Markov equivalent classes, d-separation, colliders, structural equation modeling, etc. But interest in these models began to wane as it became impossible to reasonably sample and interpret causal models of thousands of variables. By the time big collaborations on large-scale gene expression data collection in human were completed (e.g. the GTEx project), these models were largely abandoned. Indeed, the GTEx paper makes use of dead simple correlation matrices. And why not? They actually work OK for describing a global view of the data with minimal assumptions.
When testing a causal model is not up to you
This is not a flaw of causal models per se, but of neglecting the actual goals of causal models. The experimental feedback for rigorously testing causal models is a consequence of the state of a field or at the very least the place you work in. Things like optimal experimental design or refinement of causal models via randomized experiments require, well, experiments. If not everyone is on the same page, the theorists and computational folks will do their thing in isolation while the experimentalists will test whatever they think is good to test, which might not coincide with what the computational wing wants. Sometimes there’s the happy case where the modelers and experimentalists are the same, but most of the time (especially in biology), this is not the case. Causal models (like all models, really) are meant to be challenged and falsified – just make sure you’re not modeling in the vacuum.
Other approaches to causal modeling
I mainly talked about Pearl’s approach to causal modeling. But there are other approaches, each one with a unique viewpoint. Sewall Wright, which is a strong influence of Pearl’s (and in many ways his predecessor), invented path analysis in structural equation models, in which one represents a causal graph by a system of linear equations (each equation a node, each incoming edge a coefficient in the equation). Path analysis then uses traversal rules in the graph and the coefficients to compute the causal effects between any nodes in the graph. This can be seen as a specific case (where relationships are linear) of Pearl’s treatment, but by focusing on linear models, there are lots of results and short-hand rules one can use to quickly estimate causal effects.
Another interesting approach are techniques based on forecasting, like Granger causality and convergent cross mapping. Here, the focus is mostly on temporal predictions and how effective is $X$ in forecasting (temporally) $Y$ and/or how much the inverse is true. The relationships measured by these approaches are not causal in the strict, counterfactual, sense of the word, but nonetheless do give additional insights not captured by correlation alone and are easy to implement.
Philosophically, there are other ways of conceptualizing counterfactuals and causality with their own drawbacks and advantages, including how each theory deals with problems like transitivity of causal relationships and causal events that are preemptive of others. These are out of the scope of this post, but it’s worth a read in Stanford’s Encyclopedia of Philosophy.
Conclusions
I’ve been having a happy reunion with causal models and have learned a lot about the advantages, subtleties, and criticism to the approach by lurking the various conversations Pearl has with other folks in Twitter. If anything, these discussions have started to bring forth the crucial problem of non-stationary distributions that many applications of machine learning face. Learning probability distributions in general can be pretty hard, but ultimately is a static, proxy of a problem. Learning full causal models is a dynamic process in which we constantly question and our model of the world, an approach that is closer of what we actually want to do with machine learning models in a lot of cases. I’m not sure if there will be causal renaissance like deep learning, or which approach (whether Pearl’s or others’) will be deemed the best in the end. But the refresher is most welcomed.